![[www.karlson.ru]](/img/title_ru.gif)
| публикации | рисунки | фотографии | программы | ссылки |
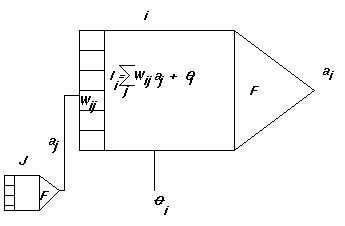
НЕМНОГО ОБ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЯХ.Кожекин Н.Интерес к нейронным сетям (также известным как PDP --- parallel distributed processing) все не ослабевает. Первая волна захлестнула научный мир в 1943 году после представления W.S.McCulloch и W.Pitts упрощенных нейронов в их классической работе "A logical calculus of the ideas immanent in nervous activity". Их нейроны рассматривались как биологические модели и как концептуальные компоненты для схем, выполняющих счетные задачи. И сейчас очень часто проводятся параллели с биологическими системами. И хотя исторически нейронные сети появились именно как модели нейронов --- клеток человеческого мозга --- такая параллель не может пониматься слишком буквально; нам до сих пор так мало известно о биологических системах, даже на нижайшем клеточном уровне, что, видимо, искусственные модели нейронных сетей сильно упрощают биологические. Вторая волна интереса к нейронным сетям родилась в начале 80-х с появлением компьютеров принципиально новых мощностей и с многими замечательными открытиями в этой области, как, например, обратное распространение ошибки (error back propogation) (Здесь и далее я буду давать многим терминам английские соответствия в скобках, за отсутствием общепринятой русскоязычной терминологии в этой области.) До сих пор эта область не до конца изучена и рождает высокую заинтересованность со стороны специалистов очень разных кругов, таких как программисты и биологи, психологи и физики. Большинство университетов имеет группы разработки на соответствующих факультетах. Попробую наиболее адекватно описать понятие нейронных сетей. Это можно сделать следующими словами. Нейронные сети --- это вычислительные модели, основными отличительными свойствами которых являются способности приспосабливаться или обучаться, обобщать или организовывать информацию, и работа которых основана на параллелизме. Многие из перечисленных свойств могут быть приписаны и к существующим ненейронным моделям. Ответ на вопрос, в каких случаях и до какой степени эффективнее использование нейронной технологии, до сих пор не получен в общем случае. Но уже сейчас, простые и не очень, нейронные сети реализуются на базе современных компьютеров. Была разработана, например, нейронная сеть, отличающая по фотографии мужское лицо от женского. Совсем легко (под силу любому школьнику, знакомому с основными понятиями теории) реализовать нейронную сеть, обыгрывающую (после достаточно большого числа шагов) человека в игру чет--нечет. Если, конечно, человек будет выкидывать ответы действительно случайно (например, бросая монетку), то будет ничья. Велик соблазн пытаться при помощи этой технологии предугадывать какие--либо псевдослучайные события, но, как нетрудно видеть, это не слишком реально. Ведь, действительно, предположим, что мы пытаемся угадывать таким образом колебания курса доллара на ММВБ. Ожидая высоких результатов надежности, мы впадем в ошибку, так как, во--первых, мы будем предугадывать лишь малые колебания (как имеющие некую определенную фиксированную тенденцию), а крупные (связанные, скажем, с каким--либо политическим обострением) действительно случайны и останутся нами незамечены, и, во--вторых, как только мы будем пытаться использовать полученные результаты, учитывая их при участии в торгах, мы будем менять те самые тенденции, позволявшие нам сделать предположение о возможности такого предсказания. В этой статье я буду пропагандировать отношение к искусственным нейронным сетям прежде всего с точки зрения науки computer science. Биологические же аспекты будут мной незаслужено проигнорированны. Далее моя статья будет состоять из трех концептуальных частей. В первой я, наконец--то, дам четкое определение искусственной нейронной сети. Во второй части я приведу в пример одну из первых и несложных, но, тем не менее, очень красивых классических теоретических моделей. И в третьей части я расскажу о возможностях применения нейронных сетей в компьютерной обработке изображений и робототехнике. Что ж это такое?Искусственная нейронная сеть строится из множества похожих друг на друга
блоков, каждый из которых производит вычисления (идея параллельных
распределенных вычислений). Каждый вычисляющий блок общается с другим
посредством передачи сигналов на "взвешенные" соединения (смысл этого
термина позже станет понятен). Примерный вид нейронной сети
показан на рисунке 1.
По топологии различаются два типа нейронных сетей: прямые, где данные передаются только вперед, и реккурентные, где могут также иметься соединения назад. Нейронную сеть надо составить так, чтобы множество входов порождало
на выходе требуемый результат, либо напрямую, либо в процессе релаксации.
Мы достигнем этого, установив веса на соединениях соответственно, используя
знания почерпнутые из тренировочных примеров, и изменяя веса по правилу
обучения. Базовая идея заключается в том, что, чем чаще
общаются нейроны ПРИМЕР: ПЕРЦЕПЦИОН `опознаватель' (perceptron)Один из самых первых классических примеров нейронной сети --
это перцепцион. Это прямая сеть, работающая с двоичными сигналами:
-1 и 1, у нее N входов и один выход, т.е. эта сеть представляет
отображение
Теперь поговорим об обучении перцепционов. Правило обучения у них чрезвычайно просто, и может быть записано в элементарной алгоритмической форме.
ПриложенияСначала поговорим о применении нейронных сетей к проблемам связанным с обработкой изображений (многое, кстати, распространяется и на звук). Обычно различают две задачи: моделирование биологических визуальных систем и компьютерная обработка изображений. Мы остановимся на последней задаче. Основная цель такой задачи -- выявить какую-либо информацию на базе двумерной матрицы (массива), состоящей из значений интенсивности цвета, называемой картинкой. Иногда рассматриваются также задачи, где входных картинок может быть несколько. А какую же информацию мы хотим получить? Есть несколько принципиальных типов: опознавание (классификация данных, причисление картинки к одному из заданных классов), геометрия (расстояние до объектов в картинке, углы, и т.д.) и сжатие (архивация картинки для ускоренной передачи или эффективного хранения). Для решения этих задач нужно проводить некие вычисления, и, так часто бывает, что эти вычисления могут проводиться независимо. Скажем, для многих задач возможно разделение картинки на сегменты, которые можно обрабатывать независимо, в этих случаях нейронная сеть может решать их очень эффективно, обрабатывая сегменты параллельно. Примерами таких задач могут служить, например, световые фильтры или определятели краев объектов в картинке. та область применения обычно называется Computer Vision, и в ней накоплен огромный опыт работы и исследований. Тем не менее, важность ее такова, что интерес к ней вряд ли остынет в недалеком будущем. Принято разделять низко-уровневые и высоко-уровневые проблемы Computer Vision. Под низко-уровневой (или early vision) обработкой изображений понимаются задачи, связанные выявлением физических свойств видимого трехмерного объекта по `картинке' (смысл этого термина мы уже вводили), в противоположность задачам высоко-уровневой обработки изображений, где основная цель -- это получение информации с разных картинок (или сегментов одной картинки) для последующего анализа при помощи высоко-уровневого знания. Пример задачи первого типа типа -- определение краев изображенного на картинке физического объекта. Хорошее определение звучит так, что это задачи обратные оптике. Напомню, что классическая оптика (или компьютерная графика) ставит задачу построения картинки по трехмерному объекту. Примером же задачи второго типа может послужить задача подсчета расстояния до объекта представленного стерео парой (то есть двумя картинками, представляющими фотографии одного объекта, как бы для левого и правого глаза). К сожалению, большинство задач Computer Vision некорректно поставленные, в точном смысле по Адамару (который правда вводил это понятие лишь применительно к задаче решения дифференциальных уравнений). То есть, как легко показать, многие из этих задач не удовлетворяют хотя бы одному из следующих требований:
Теперь разберемся с робототехникой. Основной тип индустриального робота -- это манипулятор, то есть робот способный хватать объекты, на основе информации от сенсорных датчиков. Основная задача компьютера (нейронной сети) в таком случае -- выдача директив манипулятору. Второй популярный тип роботов включает задачу планирования пути для двигающихся автономных машин. Рассмотрим принципы применения нейронных сетей на примере задачи манипуляторов. Такая задача разделяется в свою очередь на четыре:
Таковы, вкратце, основные моменты, "которые должен знать каждый", относительно искусственных нейронных сетей. Если у Вас возникли какие либо комментарии, замечания или предложения автору, Вы можете написать автору по e-mail: . |
 Пусть t время работы системы, тогда основные аспекты такой модели
можно перечислить следующим образом:
Пусть t время работы системы, тогда основные аспекты такой модели
можно перечислить следующим образом:
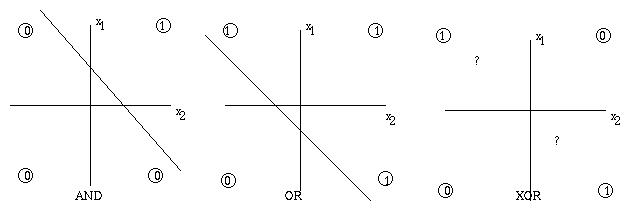 легко видеть что такую прямую можно провести для
функций логическое И (AND) и логическое ИЛИ (OR), но невозможно для
функции исключающего ИЛИ (XOR). Конечно, это не доказательство, но
читатель сам может позаботится о строгости -- это не представляет
никакого труда. Но как же решить эту проблему? Добавим один
спрятанный нейрон с двумя входами весами по 1 и сдвигом -1/2, а
выходной нейрон пусть имеет три входа, два из которых (которые ведут
от входных нейронов) имеют веса по 1 каждый, а третий (который
идет от спрятанного нейрона) имеет вес -2, и сдвиг так же -1/2.
Эту возможность можно увидеть и геометрически, перейдя в 3-х
мерное пространство и отделив нужные вершины куба плоскостью.
Теперь докажем следующую замечательную теорему.
Для любого многоуровневого перцепциона найдутся такие соединения и веса
при них, что он сможет выполнить любое заранее заданное преобразование.
Действительно, пусть нам даны N входов, которые передают сигналы M нейронам
(называемым предикатом), которые передают в свою очередь сигналы на один
выходной нейрон, конечное состояние которого (выход) обозначим за
легко видеть что такую прямую можно провести для
функций логическое И (AND) и логическое ИЛИ (OR), но невозможно для
функции исключающего ИЛИ (XOR). Конечно, это не доказательство, но
читатель сам может позаботится о строгости -- это не представляет
никакого труда. Но как же решить эту проблему? Добавим один
спрятанный нейрон с двумя входами весами по 1 и сдвигом -1/2, а
выходной нейрон пусть имеет три входа, два из которых (которые ведут
от входных нейронов) имеют веса по 1 каждый, а третий (который
идет от спрятанного нейрона) имеет вес -2, и сдвиг так же -1/2.
Эту возможность можно увидеть и геометрически, перейдя в 3-х
мерное пространство и отделив нужные вершины куба плоскостью.
Теперь докажем следующую замечательную теорему.
Для любого многоуровневого перцепциона найдутся такие соединения и веса
при них, что он сможет выполнить любое заранее заданное преобразование.
Действительно, пусть нам даны N входов, которые передают сигналы M нейронам
(называемым предикатом), которые передают в свою очередь сигналы на один
выходной нейрон, конечное состояние которого (выход) обозначим за
 ...домик на крыше...
...домик на крыше...